
La Search Console regorge de pépites parfois méconnues des utilisateurs. Parmi elles : le rapport d’exploration. Dans cet article, focus sur cette fonctionnalité qui se présente comme une alternative à un outil d’analyse de logs.
Sommaire
A quoi sert le rapport d’exploration ?
Le rapport d’exploration de la Search Console vous permet de comprendre et d’optimiser l’exploration/crawl de Googlebot. Il fournit des statistiques sur le comportement de Googlebot et son exploration. Par exemple, à quelle fréquence Googlebot explore votre site et quels sont les codes de réponse fournis.
💡 De plus, si vous n’avez pas la possibilité de procéder à une analyse de logs, le rapport de d’exploration de la Search Console est une alternative gratuite qui vous fournira des données fiables sur l’exploration de vos ressources. Il donne un accès rapide aux données sur les demandes faites à votre serveur. Il signale également les demandes qui n’ont pas atteint votre serveur et qui ne seraient donc pas signalées dans vos logs.
Qu’est-ce que le web crawling ?
Le crawling (exploration) consiste à explorer des pages et ressources d’un site web à partir d’URL que vous mettez à disposition.
Google utilise des web crawlers (robots d’exploration) comme Googlebot pour visiter vos URL, lire les informations qu’elles contiennent et suivre les liens présents dans ces pages.
💡 Les crawlers vont revisiter les pages déjà explorées pour vérifier si des changements sont apparus. Dans le même temps ces crawlers vont également vérifier si de nouvelles pages sont à explorer.

Pendant ce processus d’exploration, les crawlers doivent prendre d’importantes décisions :
- A quelle fréquence explorer les pages de votre site ?
- Quelles pages explorer ?
- Quelles pages ne pas explorer ?
Le tout en s’assurant que votre serveur peut encaisser toutes les requêtes envoyées par le robot d’exploration de Google.
✅ Les pages qui ont été explorées avec succès entreront ensuite le plus souvent dans la phase d’indexation pour apparaitre dans les résultats de recherche de Google.
Google veut s’assurer que tout cela ne surcharge pas vos serveur. C’est pourquoi la fréquence de crawl/d’exploration dépend de 3 facteurs :
- La fréquence de crawl : le nombre maximum de connexion simultanées qu’un crawler/robot d’exploration peut utiliser pour crawler un site.
- La demande de crawl : vous pouvez demander manuelle à Google d’explorer votre URL via la Search Console. Cela vous évite d’attendre que Googlebot explore votre URl quand il le décide.
- La réserve budget de crawl : les ressources allouées par Google pour explorer vos URL. Chaque site se voit allouer des ressources par Google pour explorer ses pages. Par exemple, Google sait très bien qu’un gros site comme Cdiscount a besoin d’être exploré plus fréquemment et avec plus de ressources qu’un petit site de moins de 100 pages.
Accéder au rapport d’exploration
Allez dans l’onglet Paramètres et ouvrez le rapport de statistiques sur l’exploration.
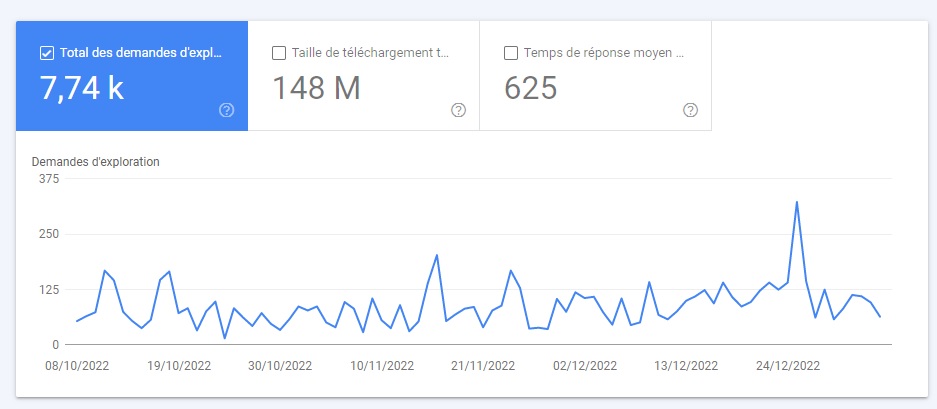
Total des demandes d’exploration
Le nombre total de requêtes d’exploration que votre domaine (ou les préfixes d’URL) a reçu au cours des 90 derniers jours. C’est un excellent moyen d’analyser si le nombre de demandes d’exploration est bien corrélé avec le nombre de pages que vous souhaitez faire explorer.
Taille de téléchargement totale
Le robot d’un moteur de recherche vérifie tout ce qui est disponible sur votre site web, y compris les fichiers et les ressources. Ces ressources sont calculées en octets et comprennent les fichiers HTML, les octets d’images associées, les fichiers de scripts et les fichiers CSS.
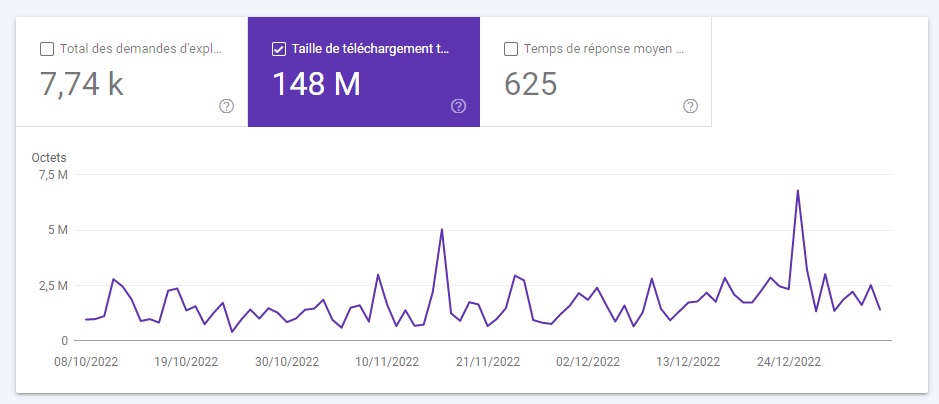
Certains indices montrent que la taille totale du téléchargement est plus représentative du budget d’exploration que le nombre total de demandes d’exploration.
Par exemple, Google peut crawler beaucoup plus de pages 404 que de pages renvoyant un code de statut 200. Cela s’explique par le fait que Google n’a besoin que de récupérer le code de statut pour les premières, et qu’il doit retourner la page pour les suivantes.
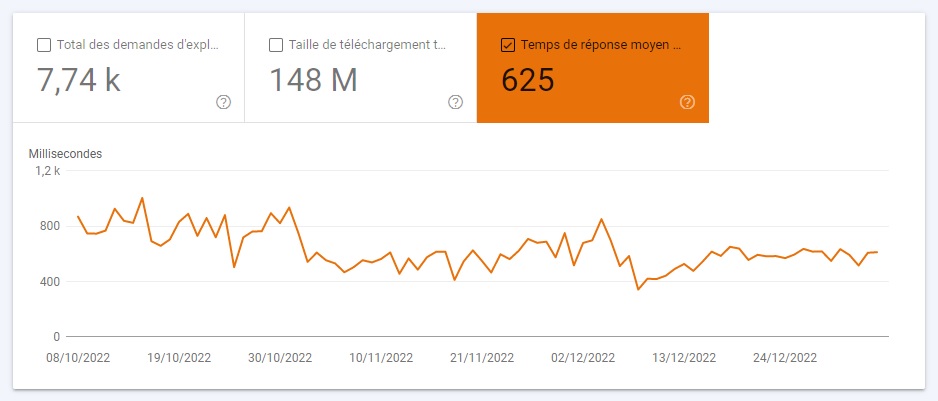
Temps de réponse moyen
Le temps de réponse moyen est associé au temps que prend un robot pour rassembler les ressources de la page. Il est également connu sous le nom de temps de rendu de la page : en gros, le temps qu’il faut pour que la page se charge et que l’utilisateur puisse interagir avec.
Etat de l’hôte
Cette section vous montre spécifiquement les tendances sur la façon dont vos préfixes d’URL sont explorés et s’il y a des problèmes.

Vous pouvez accéder à un rapport de crawl spécifique à ces préfixes et signaler des problèmes liés au robots.txt, la résolution DNS et la connectivité du serveur.
Le détail des demandes d’exploration
La ventilation des requêtes de crawl vous donne une vue globale de vos données de crawl sur 90 jours. Voici les catégories qui font partie de cette section :
Par réponse
Ce rapport est divisé en codes de statut de réponse HTTP. Vous pouvez creuser plus profondément dans 200 (accessible), 301 (déplacé définitivement), 304 (non modifié), 302 (déplacé temporairement), 404 (non trouvé) …

👉 Ici, on voit que le site renvoie majoritairement un code de réponse 200, ce qui est classique.
Petite astuce : nous vous recommandons d’utiliser le code 304 pour des ressources javascript et CSS qui ne sont jamais modifiées. En effet, ce code de réponse indique à Google que la ressource n’a pas bougé et lui évite ainsi de gaspiller du budget de crawl en l’explorant.
Par type de fichier
Similaire au rapport par réponse, mais séparé par le type de ressources sur votre site web : HTML, Javascript, CSS, Images, JSON… Ce rapport peut vous en dire beaucoup sur votre thème WordPress ! En effet, nous voyons ici que la JSON (un dérivé du Javascript) représente le principal type de fichier exploré par le crawler de Google.

Par objectif
Il s’agit soit d’une « actualisation », soit d’une « découverte ». Vous avez des pages qui sont à nouveau explorées par Googlebot ou vous avez de nouvelles pages/ressources qui ont été découvertes. Si vous voyez des pages qui ne sont pas censées être indexées, vous pouvez facilement les identifier et résoudre les problèmes d’indexation.

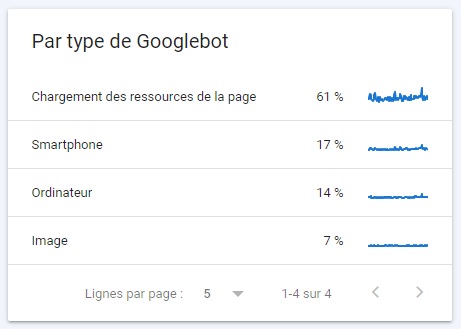
Par type de Googlebot
Il s’agit du type de robot d’exploration Google qui parcourt votre site web. Smartphone, chargement des ressources de la page, ordinateur… Il est ici possible de comprendre la façon dont votre site web est exploré en connaissant le type de robots qui l’explorent.
👉 Dans l’exemple ci-dessous, on constate facilement que le site en question présente un problème : 61% du temps, les robots d’exploration explorent des ressources de la page : Javascript, JSON, Ajax…
Cela est souvent la preuve que la CMS ou le thème choisi est trop lourd ! Généralement, pour un site présent dans l’index mobile first, Googlebot Smartphone devrait représenter entre 25% et 50% de l’exploration.
Pour plus d’infos, Google a publié la vidéo ci-dessous pour vous présenter cet outil. 👇
0 commentaires