
Google met désormais à disposition SynthID, sa technologie de watermarking et de reconnaissance de textes d’intelligence artificielle, en open source.
La quantité croissante de contenus IA sur le web devient de plus en plus problématique. D’une part, la qualité en pâtit, car au lieu de créer de nouveaux contenus, l’IA se contente de préparer des contenus existants. D’autre part, l’IA génère également une quantité croissante de contenus erronés, que ce soit volontairement ou par erreur.
C’est pourquoi la reconnaissance la plus fiable possible du contenu de l’IA revêt une importance capitale. Google a développé SynthID pour reconnaître l’origine IA des textes et pour apposer un filigrane numérique sur ces textes. Au printemps de cette année, la firme de Mountain View a rendu possible l’utilisation de SythID pour son propre Large Language Model Gemini et pour le modèle vidéo Veo, également maison, et a annoncé en même temps que SynthID serait mis à disposition en open source dans le courant de l’année.
C’est exactement ce qui s’est passé. Google l’a annoncé sur X.
👉 SynthID peut être téléchargé soit via HuggingFace, soit via le Responsible GenAI Toolkit.
Comment ça fonctionne ?
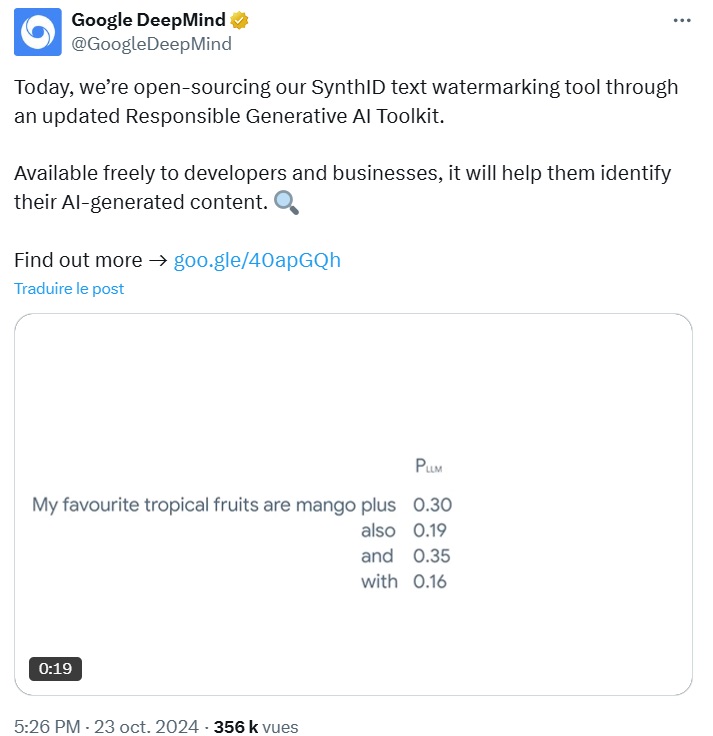
Le watermarking de textes se base sur la propriété des grands modèles linguistiques de prédire la probabilité des tokens. Un jeton peut être un caractère unique, mais aussi un mot ou une phrase. Une certaine valeur de probabilité est attribuée à chaque token possible. Les tokens ayant une valeur plus élevée ont plus de chances d’être utilisés. Un Large Language Model répète la sélection de tokens afin de produire des réponses cohérentes.
SynthID crée des filigranes non reconnaissables par l’homme lors de la génération de texte. Pour ce faire, des informations supplémentaires sont introduites dans la distribution des tokens en modulant la probabilité d’utilisation des tokens. La qualité, la précision, la créativité et la vitesse de génération du texte ne sont pas affectées.
De cette manière, les textes filigranés peuvent être reconnus de manière assez fiable. L’exemple suivant d’un e-mail généré par l’IA permet de le visualiser :

Google reconnaît toutefois lui-même que SynthID n’est pas l’arme universelle pour reconnaître les contenus générés par l’IA. Il s’agit néanmoins d’un élément qui permet de créer des outils plus fiables pour la reconnaissance de contenus d’IA. La reconnaissance est par exemple limitée pour les textes courts ainsi que pour les textes IA qui ont été entièrement réécrits ou traduits. La reconnaissance par SynthID est également limitée pour les réponses à des questions factuelles telles que « Quelle est la capitale de l’Allemagne » ainsi que pour les invites dont les réponses ne devraient pas ou peu varier.
Néanmoins, SynthID offre de bien meilleures possibilités de reconnaissance de contenus d’IA que de nombreux outils existants, ce qui est à saluer au vu de la part déjà importante de contenus générés par des machines sur le web.
0 commentaires