Le fichier robots.txt est une partie souvent négligée et parfois oubliée d’un site web et du référencement. Voyons ensemble sa définition, des exemples concrets d’application et des astuces pour l’exploiter efficacement.
Le fichier robots.txt est une partie importante de votre stratégie SEO, que vous soyez ou non débutant dans le secteur ou que vous soyez un vétéran du référencement.
Sommaire
🤖 Qu’est-ce qu’un fichier robots.txt ?
Un fichier robots.txt est un fichier texte qui peut être utilisé à des fins diverses, qu’il s’agisse de faire savoir aux moteurs de recherche où aller pour localiser le fichier Sitemap de votre site, de leur indiquer les pages à explorer ou non, ou encore d’être un excellent outil pour gérer le budget de crawl de votre site.
💡 Qu’est-ce que le budget de crawl ?
Le budget de crawl représente les ressources que Google utilise pour explorer et indexer efficacement les pages de votre site. Aussi grand que soit Google, il n’a encore qu’un nombre limité de ressources disponibles pour pouvoir explorer et indexer le contenu de vos sites.
Si votre site n’a que quelques centaines d’URL, Google devrait être en mesure d’explorer et d’indexer facilement les pages de votre site.
En revanche, si votre site est volumineux, comme un site e-commerce par exemple, et que vous avez des milliers de pages avec de nombreuses URL générées automatiquement, il se peut que Google n’explore pas toutes ces pages et que vous manquiez beaucoup de trafic potentiel et de visibilité.
C’est là qu’il devient important de définir des priorités quant au contenu, au moment et à la quantité de pages à explorer.
Google a déclaré qu’avoir de nombreuses URL à faible valeur ajoutée peut avoir un effet négatif sur l’exploration et l’indexation d’un site. C’est là qu’un fichier robots.txt peut vous aider à gérer les facteurs qui influencent le budget d’exploration de votre site.
Vous pouvez utiliser ce fichier pour vous aider à gérer le budget de crawl de votre site, en vous assurant que les moteurs de recherche passent leur temps sur votre site aussi efficacement que possible (surtout si vous avez un grand site), en n’explorant que les pages importantes et en ne perdant pas de temps sur des pages telles que les pages de connexion, d’inscription ou de remerciement. Pensez donc à analyser ce fichier si vous opérez l’audit SEO d’un site.
👍 Pourquoi avez-vous besoin du robots.txt ?
Avant qu’un robot d’indexation tel que Googlebot ou Bingbot ne parcoure une page web, il vérifiera d’abord s’il existe un fichier robots.txt et, s’il en existe un, il suivra et respectera généralement les instructions contenues dans ce fichier.
Un fichier robots.txt peut être un outil puissant dans l’arsenal de tout référenceur car c’est un excellent moyen de contrôler la façon dont les robots des moteurs de recherche accèdent à certaines zones de votre site. N’oubliez pas que vous devez vous assurer que vous comprenez le fonctionnement du fichier robots.txt, sinon vous vous retrouverez accidentellement à empêcher Googlebot ou tout autre robot d’explorer l’ensemble de votre site et de ne pas le trouver dans les résultats de recherche !
Cependant, lorsqu’il est bien fait, le robots.txt vous permet contrôler des choses telles que:
- Bloquer l’accès à des sections entières de votre site (environnement de développement, staging, pré-production).
- Empêcher que les pages de résultats de recherche interne de votre site soient explorées, indexées ou apparaissent dans les résultats de recherche.
- L’emplacement de vos fichiers fichiers Sitemaps XML.
- Optimiser le budget de crawl en bloquant l’accès aux pages de faible valeur (login, remerciements, paniers d’achat etc.)
- Empêcher l’indexation de certains fichiers de votre site web (images, PDF, etc.)
Exemples de fichiers robots.txt
Vous trouverez ci-dessous quelques exemples de la manière dont vous pouvez utiliser le fichier robots.txt sur votre propre site.
Permettre à tous les crawlers/robots d’accéder au contenu de votre site :
User-agent: *
Disallow:
Bloquer tous les crawlers/bots d’explorer tous les contenus de votre site :
User-agent: *
Disallow: /
Vous pouvez voir à quel point il est facile de faire une erreur lors de la création de votre fichier robots.txt car la différence avec le blocage de votre site entier est une simple barre oblique dans la directive d’interdiction (Disallow : /).
Bloquer un crawler/bot spécifique d’explorer un dossier spécifique :
User-agent: Googlebot
Disallow: /robe/
Bloquer un crawler/bot d’explorer une page spécifique :
User-agent:
Disallow: /login.html
Exclure tous les robots d’une partie du serveur :
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /junk/
Voici un exemple de ce à quoi ressemble le fichier robots.txt du laredoute.fr :
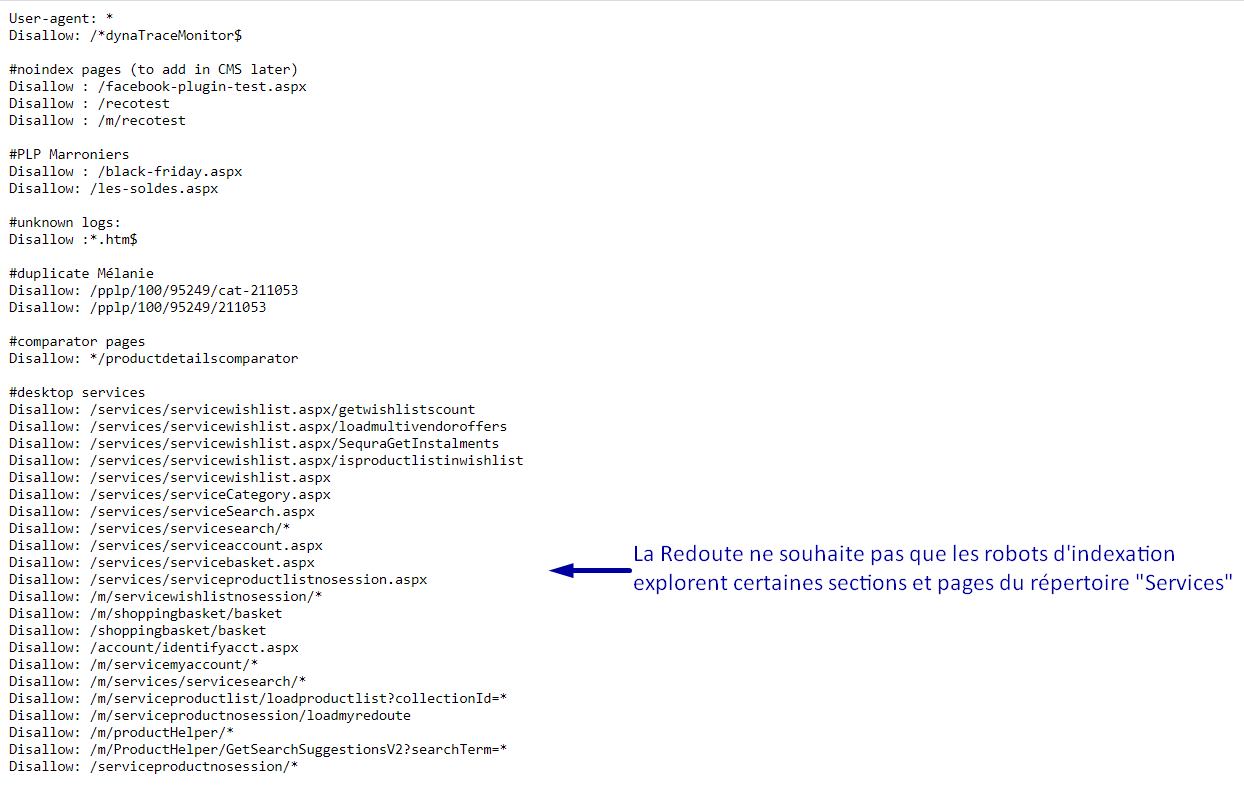

Le fichier d’exemple peut être consulté ici : https://www.laredoute.fr/robots.txt
Il est important de se rappeler que si vous voulez vous assurer qu’un robot ne parcourt pas certaines pages ou certains répertoires de votre site, vous devez les indiquer dans les déclarations « Disallow » de votre fichier robots.txt, comme dans les exemples ci-dessus.
Vous pouvez voir comment Google gère le fichier robots.txt dans son guide des spécifications de robots.txt. Google a actuellement une limite de taille maximale pour le fichier robots.txt qui est fixée à 500KB, il est donc important de faire attention à la taille du fichier robots.txt de votre site.
⚙️ Comment créer un fichier robots.txt ?
La création d’un fichier robots.txt pour votre site est un processus assez simple qui requiert de créer un fichier en format texte. Cependant, il est aussi facile de faire une erreur. Ne laissez pas cela vous décourager de créer ou de modifier un fichier robots.txt pour votre site.
Cet article de Google vous guide à travers le processus de création du fichier robots.txt et devrait vous aider à vous sentir à l’aise pour créer votre propre fichier.
Une fois que vous serez à l’aise pour créer ou modifier le fichier robots de votre site, Google propose un autre excellent article qui explique comment tester le fichier robots.txt de votre site pour voir s’il est correctement configuré.
✅ Vérifier si vous avez un fichier robots.txt
Si vous êtes novice ou si vous n’êtes pas sûr que votre site en possède un fichier robots.txt, vous pouvez faire une vérification rapide pour le voir. Tout ce que vous devez faire pour vérifier est d’aller à la racine de votre site et d’ajouter /robots.txt à la fin de l’URL. Exemple : www.votresite.fr/robots.txt
Si rien n’apparaît, c’est que vous n’avez pas de fichier robots.txt pour votre site. C’est le moment idéal pour tester la création d’un fichier.
👉 Les meilleures pratiques
- Assurez-vous que toutes les pages importantes sont explorables et que les contenus qui n’ont pas de valeur réelle, s’ils sont trouvés lors d’une recherche, sont bloqués.
- Ne bloquez pas les fichiers JavaScript et CSS de vos sites.
- Vérifiez toujours rapidement votre fichier robots.txt pour vous assurer que rien n’a changé par accident.
- Capitalisation correcte des noms de répertoires, sous-répertoires et fichiers.
- Placez le fichier robots.txt dans le répertoire racine de votre site web pour qu’il soit trouvé.
- Le fichier doit être nommé « robots.txt » et rien d’autre.
- N’utilisez pas le fichier robots.txt pour masquer les informations privées des utilisateurs car elles seront toujours visibles.
- Ajoutez l’emplacement de votre Sitemap à votre fichier robots.txt.
- Assurez-vous que vous ne bloquez aucun contenu ou section de votre site web que vous souhaitez explorer.
🤔 Cas spécifiques
Si vous avez un ou plusieurs sous-domaines sur votre site, vous devrez avoir un fichier robots.txt sur chaque sous-domaine ainsi que sur le domaine racine principal. Ce fichier ressemblerait à ceci : boutique.votresite.fr/robots.txt et votresite.fr/robots.txt.
Comme mentionné ci-dessus dans la section des meilleurs pratiques, il est important de ne pas utiliser le fichier robots.txt pour éviter que des données sensibles, telles que des informations privées sur l’utilisateur, soient explorées et apparaissent dans les résultats de recherche.
La raison en est qu’il est possible que d’autres pages renvoient à ces informations et que, s’il existe un lien direct vers le site, les règles du fichier robots.txt seront contournées et le contenu pourra quand même être indexé. Si vous devez empêcher vos pages d’être réellement indexées dans les résultats de recherche, utilisez une méthode différente comme l’ajout d’une protection par mot de passe ou l’ajout d’une balise meta noindex à ces pages. Google ne peut pas se connecter à un site ou à une page protégés par un mot de passe, et ne peut donc pas explorer ou indexer ces pages.
Conclusion
Même si vous n’avez jamais travaillé sur le fichier robots.txt auparavant, soyez assuré qu’il est assez simple à utiliser et à configurer. Une fois que vous serez à l’aise avec les tenants et aboutissants du fichier robots.txt, vous pourrez améliorer le référencement de votre site et aider les robots des moteurs de recherche.
En configurant correctement votre fichier robots.txt, vous aiderez les robots des moteurs de recherche à dépenser judicieusement leur budget de crawl et à ne pas perdre leur temps et leurs ressources à explorer des pages qui n’ont pas besoin d’être explorées. Cela les aidera à organiser et à afficher le contenu de vos sites dans les SERP de la meilleure façon possible, ce qui signifie que vous aurez plus de visibilité.
N’oubliez pas qu’il ne faut pas nécessairement consacrer beaucoup de temps et d’efforts à la configuration de votre fichier robots.txt. La plupart du temps, il s’agit d’une installation unique, que vous pouvez ensuite modifier et ajuster pour mieux sculpter votre site.
0 commentaires